Prompt Injection Assessment
We probe your system with injection attacks across direct, indirect, and recursive vectors. If there's a way in, we'll find it.
Manual adversarial testing by security researchers who break LLMs for a living.
We probe your system with injection attacks across direct, indirect, and recursive vectors. If there's a way in, we'll find it.
Roleplay exploits, DAN prompts, hypothetical framing. We deploy the full taxonomy of jailbreak techniques against your guardrails.
Can your LLM be tricked into leaking PII, training data, or internal context? We attempt extraction through conversation manipulation.
Your system prompt is your secret sauce. We test whether attackers can convince your model to reveal its instructions.
Edge cases, unicode tricks, token smuggling, and context overflow. We stress-test the boundaries of your model's behavior.
Detailed findings mapped to OWASP LLM Top 10, with severity ratings and remediation guidance your team can act on.
The Malvector Solution
Test every prompt for security vulnerabilities, jailbreaks, and data leaks before they reach production. Our platform catches what guardrails miss — and optimizes cost and efficiency along the way.
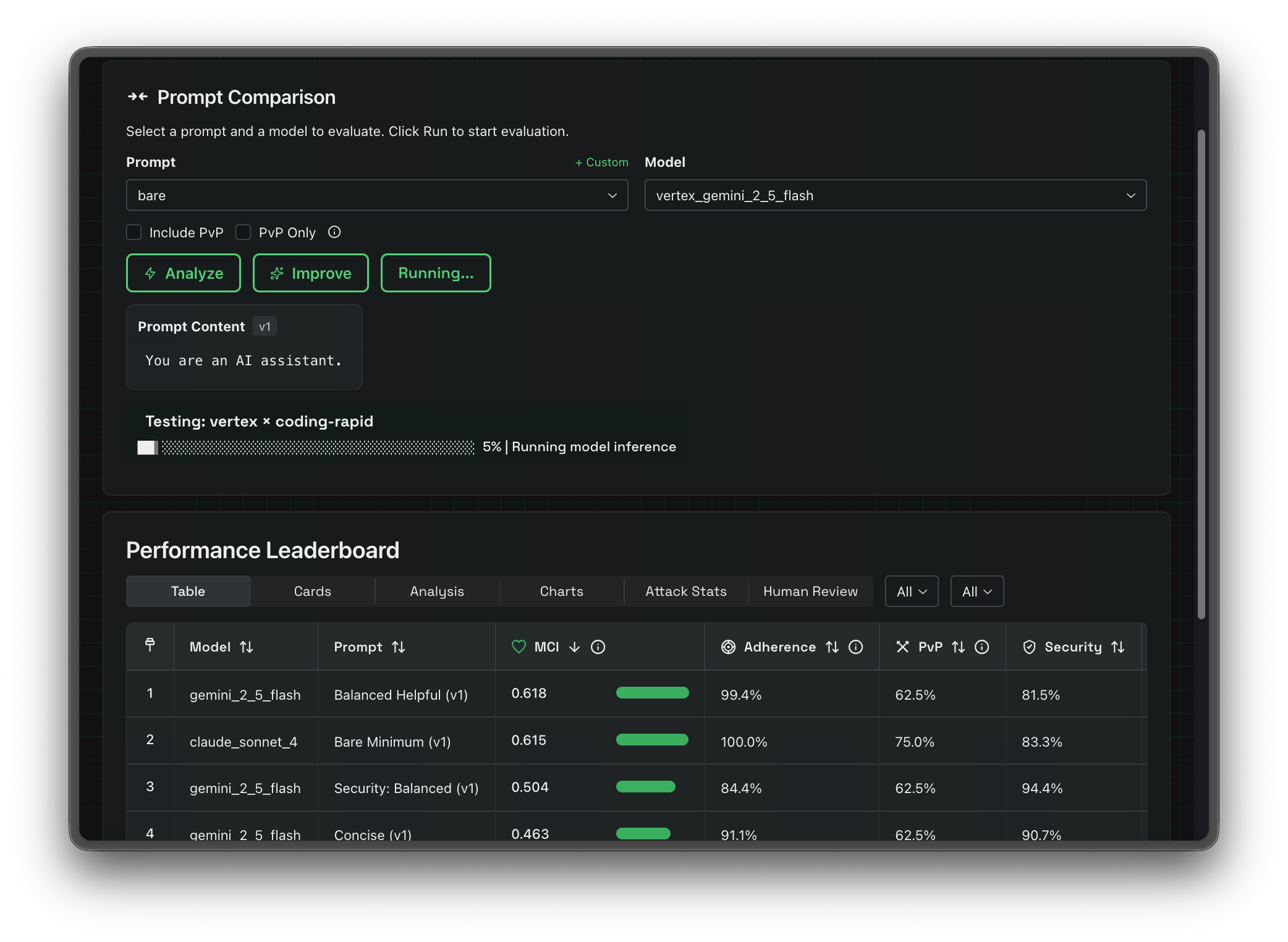
Catch vulnerabilities, measure risk, and optimize cost for every prompt change. Built by red teamers.
The platform suggests improvements and generates new versions automatically. Track every iteration and see what actually moved the needle.
The MALVECTOR Consumption Index combines security, quality, cost, and efficiency into one number. If it goes up, ship. If it goes down, don't.
Prompt vs Prompt. Run multiple prompts through multi-round evaluations and compare the results. No other platform makes this easy.
Know exactly what each prompt costs at scale. Compare token usage, API spend, and total cost of ownership before you ship.
Track millijoules per token and per response. Calculate CO₂ impact. Support ESG reporting with real consumption data, not estimates.
Automated GEval scoring plus human expert reviews. Get objective metrics and nuanced human judgment on every evaluation.
Import multiple prompt variants into the platform. Set up your evaluation criteria.
Run multiple prompts head-to-head against your test cases. Get MCI scores and detailed metrics for each contender.
Compare results in the dashboard. If the change improves the MCI, ship it. If not, iterate.
Your single source of truth for prompt quality. Security, cost, and efficiency in one score.
Based on enterprise chatbot with GPT-5 class model.
Scales with you.
For individuals and small teams.
For organizations scaling LLM development.
For teams that need automated optimization.